ServerLoadSpreading
Like Peanut Butter on Toast
Say you have a process that runs on lots and lots of servers and you want to make sure it doesn't execute on every machine at the same time. What's the best way to design that setup? How can you measure the effectiveness of your solution?
I recently had to implement a system like this at my work. In this case we had about 10,000 servers and an update process that had to run once per day per machine. It was desirable that the update process run on as few machines concurrently as possible. My first guess at how to implement load spreading was by using something simple like the bash $RANDOM pseudorandom number generator. But, is that sufficient to adequately spread the load? I started thinking about other alternatives and hit on the idea of using a hashing function. I then decided to take the next step and try to compare the two methods empirically. The rest of this post explains that process and my conclusions.
First Stab
Like I said, I'm working with about 10,000 servers here. I also have an account on every machine and a massively parallel ssh execution engine. Thus, running commands on all the servers and collecting results is a fairly trivial operation.
When I originally started developing the spreading mechanism, my first thought was to use a random delay in a bash script, something like this:
sleep `expr $RANDOM % 86400`
on every host. Yes, I know that could be done in modern bash as sleep $($(($RANDOM%86400+1))) but for various reasons I need to stick with stock bourne shell functionality. Also I realize that not all days have 86400 seconds in them but lets sweep that under the rug for now.
Turns out this doesn't work, because bash $RANDOM is a signed 16-bit integer so it only goes to 32767. So I embiggened it:
sleep `expr $RANDOM * 3 % 86400`
That produced numbers in the range I was looking for so I used it for the rest of my testing.
Perl?
Hey wait a second - can't I do this with perl? The answer is of course yes. In fact, perl offers a nice command line shortcut for generating random numbers:
perl -le 'print int rand(86400)'
that offers several advantages over using the builtin bash $RANDOM
- supports arbitrarily large integers
- uses much better pseudorandom algorithm
I ended up testing this mechanism as well and you will find my results below.
Perl Hostname Hashing
However, I still wasn't done. Could I find a better mechanism than random numbers? Based on some conversations with coworkers, I started thinking about hostname hashing. Disclaimer: I did not come up with this idea myself, although I did develop this particular implementation.
A hash function is an algorithm that takes input values and puts them into buckets. The goal is to spread the input into the buckets evenly. A phone book is an example of a (terrible) hash function - it maps names to alphabetical sections. It's a terrible hash function because there are many more names in the US that start with 'M' than with 'Z', so it doesn't spread the input between the buckets very well.
Every server has a unique identifier - the fully qualified hostname. Thus I just needed a hash function that took the hostname and converted it to a number between 1 and 86400. Perl has an internal hashing function which is exposed through the perl compiler backend module 'B'. I wrote the following perl code to use it:
use B;
sub compute_hash
{
my ($string,$range) = @_;
my $hc = hex(B::hash $string);
return $hc % $range;
}
which I then distilled down to a perl oneliner:
perl -MB -MSys::Hostname -le "print hex(B::hash hostname) % 86400"
Testing the Alternatives
As I mentioned, I have a massively parallel ssh execution engine at my disposal. That makes testing easy - just launch a job on every host and collect the results. I realize that I could just calculate the perl hash values for hostnames without logging in to every machine, but I had the setup all ready to go for the random values so it was easier to log on to the host for each test.
I ran a job on every host and collected the output in a file in the format
hostname1.example.com 81221 hostname2.example.com 3 hostname3.examplecom 2210
and so on. I repeated that process for each of my three methodologies (bash random, perl random, perl hash). That gave me the raw data which I then needed to collate with the following perl script:
#!/usr/bin/perl
# randomer.pl
# process input in form of
# <hostname> <delay>
#
#and transform into
#
# <delay> <count>
#
# suitable for frequency plotting.
use warnings;
use strict;
my %counter = ();
while(<>)
{
(my $delay) = (/^\S+\s+(\S+)/);
$counter{$delay}++;
}
foreach (sort {$a<=>$b} keys %counter)
{
print $_ . " " . $counter{$_} . "\n";
}
which resulted in output like this, suitable for plotting in gnuplot:
1 1 2 1 3 1 7 1 30 1 42 1 47 1 49 1 66 1 71 1 96 1 112 1 126 1 134 1 136 1 140 1
etc.
Here's the gnuplot control file I used to generate the graphs:
set terminal png size 1000,300 font "/Library/Fonts/Andale Mono.ttf" 12 set output "spread-perl-hash.png" set xrange [0:86400] set yrange [0:4] set xlabel "delay (s)" set ylabel "# of hosts" set title "collisions using perl \"int(rand())\" for delay value - 10197 hosts, 86400s spread" set ytics 1 set xtics nomirror set ytics nomirror set key off plot "perl-hash-freq.txt" using 1:2 index 0 title "number of collisions" pt 6 lt 2
The Results
Here then are my three graphs, with a collision count for each one. First, the bash random number approach:
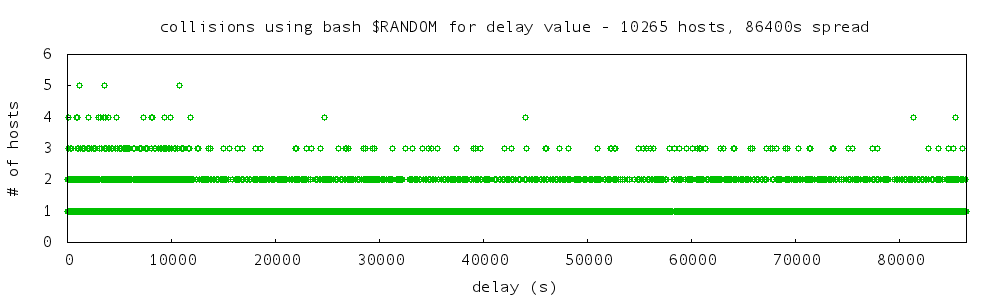
- 6989 occasions no collisions
- 1314 occasions one collision
- 183 occasions two collisions
- 21 occasions three collisions
- 3 occasions four collisions
- no occurrences of more than four collisions
Next, the perl random number approach:
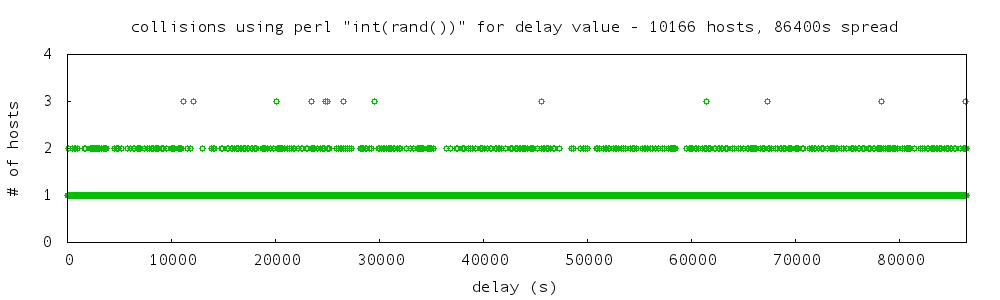
- 9047 occasions no collisions
- 540 occasions one collision
- 13 occasions two collisions
- no occurences of more than two collisions
Finally, the perl hostname hash approach:

- 9009 occasions no collisions
- 558 occasions one collision
- 24 occasions two collisions
- no occurrences of more than two collisions
Conclusion
As you can see from the numbers, the perl approach outperforms the bash random approach significantly, with many fewer collisions. The perl random approach performs the best with the fewest collisions of the three mechanisms. Remember, fewer collisions means fewer hosts executing the update at the same time.
In reality, any of these techniques is probably enough spread for my needs - I don't need an absolute guarantee that no two hosts execute at the same time, I just want to minimize that possibility. The hash approach could probably be improved by the use of a stronger hash function as the default perl hash function is optimized for speed.
In the end I went with the perl hash approach because of it's repeatability. Since the hash value on a given host never changes (as long as the hostname doesn't change), every day the same host executes at exactly the same time. Thus while the hashed approach is not quite the best spread, you also know it will never end up any worse. With a random approach there's always an infinitesimal chance that every host could run at the exact same second of a particular day.
I'd like to finish all this with a word about devops. I'm a system administrator by trade, although I do have a computer science degree. Devops is all about tying developers and operations folks together and improving communication. A large part of that is bringing developer tools to the operations side of the house. There's no reason why operations folks have to rely on developers to write tools like server load spreading algorithms. Hopefully I've shown in this post that anyone can apply a little bit of logical thinking and a little bit of code to try to answer real operational questions.
Further Reading
A perlmonks discussion on perl hash internals.
A description of how hashes really work.
How to call the perl hash function directly.
More than you could ever want to know about hashing.

